漏洞原理
PHP反序列化漏洞
序列化
序列化就是将对象object、字符串string、数组array、变量,转换成具有一定格式的字符串,使其能在文件储存或传输的过程中保持稳定的格式。
PHP中通过 serialize() 函数实现
例如:
1 |
|
序列化的结果为
1 | O:6:"Person":3:{s:4:"name";s:3:"Tom";s:11:"Personage";i:18;s:6:"*sex";s:4:"male";} |
其中
1 | O代表object,如果是数组则是i,6代表对象名长度,Person是对象名 |
1 | 根据成员变量的的修饰类型不同,在序列化中的表示方法也有所不同 |
反序列化
反序列化就是序列化的逆过程,通过 unserialize() 函数实现
1 |
|
结果不含类方法:
1 | object(Person)#2 (3) { |
PHP魔术方法
1 | __construct():构造函数,此函数会在创建一个类的实例时自动调用。 |
执行的顺序(如果全部执行的话)
1 | new obj->serialize obj->unserialize str[->str(obj)]->end |
函数绕过
1 | 当成员属性数目大于实际数目时可绕过wakeup方法(CVE-2016-7124) |
应用场景
可用的类,类中有魔法函数,unserialize的参数用户可控。攻击者可以构造恶意的序列化字符串
PHP伪协议
简介
PHP 伪协议 是 PHP 支持的协议与封装协议,可利用这些协议完成许多命令执行
php支持的12个伪协议
1 | file:// 访问本地文件系统 |
前提
1 | php.ini里有两个参数 |
伪协议
file://
用于访问本地文件系统,并且不受allow_url_fopen,allow_url_include影响
file://协议主要用于访问文件(绝对路径、相对路径以及网络路径)
1 | 例如:http://www.xx.com?file=file:///etc/passsword |
php://
在allow_url_fopen,allow_url_include都关闭的情况下可以正常使用php://作用为访问输入输出流
php://input
php://input可以访问请求的原始数据的只读流,将post请求的数据当作php代码执行。当传入的参数作为文件名打开时,可以将参数设为php://input,同时post想设置的文件内容,php执行时会将post内容当作文件内容。从而导致任意代码执行。
1 | allow_url_fopen=on and allow_url_include=on |
例如
1 | url: /?file=php://input |
PHP://filter
php://filter 是一种元封装器, 设计用于数据流打开时的筛选过滤应用。 这对于一体式(all-in-one)的文件函数非常有用,类似 readfile()、 file() 和 file_get_contents(), 在数据流内容读取之前没有机会应用其他过滤器。
简单通俗的说,这是一个中间件,在读入或写入数据的时候对数据进行处理后输出的一个过程。
php://filter可以获取指定文件源码。当它与包含函数结合时,php://filter流会被当作php文件执行。所以我们一般对其进行编码,让其不执行。从而导致任意文件读取。
1 | resource=<要过滤的数据流> 这个参数是必须的。它指定了你要筛选过滤的数据流。 |
例如:
1 | php://filter/read=convert.base64-encode/resource=index.php |
1 | 利用filter协议读文件,将index.php通过base64编码后进行输出。这样做的好处就是如果不进行编码,文件包含后就不会有输出结果,而是当做php文件执行了,而通过编码后则可以读取文件源码。 |
data://
1 | allow_url_fopen:on |
数据流封装器,以传递相应格式的数据。可以让用户来控制输入流,当它与包含函数结合时,用户输入的data://流会被当作php文件执行。
例如
1 | 1、data://text/plain, |
1 | 比如:http://www.xx.com?file=file:///etc/passsword |
phar://、zip://、bzip2://、zlib://
1 | allow_url_fopen:off/on |
1 | phar://[压缩文件路径]/[压缩文件内的子文件名] |
zip:// 可以访问压缩包里面的文件。当它与包含函数结合时,zip://流会被当作php文件执行。从而实现任意代码执行。
1 | zip://中只能传入绝对路径。 |
例如:

过滤器
字符串过滤器
1 | string.rot13 |
转换过滤器
1 | 对数据流进行编码,通常用来读取文件源码。 |
1 | UCS-4* |
压缩过滤器
压缩过滤器指的并不是在数据流传入的时候对整个数据进行写入文件后压缩文件,也不代表可以压缩或者解压数据流。
压缩过滤器不产生命令行工具如 gzip的头和尾信息。只是压缩和解压数据流中的有效载荷部分。
1 | 用到的两个相关过滤器:zlib.deflate(压缩)和 zlib.inflate(解压)。zilb是比较主流的用法,至于bzip2.compress和 bzip2.decompress工作的方式与 zlib 过滤器大致相同。 |
加密过滤器
1 | mcrypt.*和 mdecrypt.*使用 libmcrypt 提供了对称的加密和解密。 |
死亡绕过
死亡exit指的是在进行写入PHP文件操作时,执行了以下函数:
1 | file_put_contents($content, '<?php exit();' . $content); |
这样当插入木马后,会先执行exit
1 | exit(); |
三种类型
1 | file_put_contents($filename , "<?php exit();".$content); |
第一种
1 | file_put_contents($filename , "<?php exit();".$content); |
base64decode绕过
1 | $filename是控制文件名的,如果我们使用php://filter协议的话,这会先按php://filter规定的协议对$content进行解码后再写入协议 |
1 | $content = '<?php exit; ?>'; |
base64编码中只包含64个可打印字符,当PHP遇到不可解码的字符时,会选择性的跳过,这个时候base64就相当于以下的过程
1 | $_GET['txt'] = preg_replace('|[^a-z0-9A-Z+/]|s', '', $_GET['txt']); |
所以,当$content 包含 <?php exit; ?>时,解码过程会先去除识别不了的字符,< ; ? >和空格等都将被去除,于是剩下的字符就只有phpexit以及我们传入的字符了。
由于base64是4个byte一组,再添加一个字符例如添加字符a后,将phpexita当做两组base64进行解码,也就绕过这个死亡exit了。
例如:
1 | php://filter/convert.base64-decode/resource=shell.php&content=aPD9waHBpbmZvKCk7Pz4= |
rot13编码绕过
1 | php://filter/string.rot13/resource=adam.php |
.htaccess的预包含利用
string.strip_tags能够从字符串中取出HTML和PHP标记,尝试返回给定的字符串 str 去除空字符,HTML和PHP标记后的结果。
1 | $filename=php://filter/write=string.strip_tags/resource=.htaccess |
1 | string.strip_tags过滤了.htaccess内容的html标签和PHP标记 |
注意
1 | 1.win10中路径需要两个反斜杠\\。 |
过滤器编码组合
例如,先去标签,再解码
1 | $filename='php://filter/string.strip_tags|convert.base64-decode/resource=s1mple.php' |
如果是php7的话
1 | http://localhost/test1.php?filename= |
1 | $filename='php://filter/zlib.deflate|string.tolower|zlib.inflate|/resource=adam.php'; |
先压缩,然后小写,然后解压缩,不过可能这是个特殊情况
第二种
1 | file_put_fontents($content,"<?php exit();".$content); |
base64
这里使用base64会报错
1 | php://filter/convert.base64-decode/resource=PD9waHAgcGhwaW5mbygpOz8+.php |
=在base64中的作用是填充,在=的后面是不允许有任何其他字符的否则会报错,有的解码程序会自动忽略后面的字符从而正常解码,其实实际上还是有问题的。
所以需要想办法去掉=
去掉等号之过滤器嵌套base64
1 | php://filter/string.strip.tags|convert.base64-decode/resource=?>PD9waHAgcGhwaW5mbygpOz8%2B.php |
可以生成文件,但是访问不到,这是因为引号的问题,可以使用伪目录的方法绕过
1 | php://filter/write=string.strip_tags|convert.base64-decode/resource=?>PD9waHAgcGhwaW5mbygpOz8%2B/../s1mple.php |
去掉等号之直接对内容进行变性另类base64
1 | php://filter/<?|string.strip_tags|convert.base64-decode/resource=?>PD9waHAgcGhwaW5mbygpOz8%2B/../s1mple.php |
这种payload的攻击原理即是首先直接在内容时,就将我们base64遇到的‘=’这个问题直接写在<? ?>中进行过滤掉,然后base64-decode再对原本内容的<?php exit();进行转码,从而达到分解死亡代码的效果;这是两种攻击思路;
rot13
和第一种类型一样
1 | php://filter/write=string.rot13|<?cuc cucvasb();?>|/resource=s1mple.php |
第三种情况
1 | file_put_contents($filename,$content . "\nxxxxxx") |
这种情形一般考点都是禁止有特殊起始符和结束符号的语言
举个例子,如果题目没有ban掉php,那么我们可以轻而易举的写入php代码,因为php代码有特殊的起始符和结束符,所以后面的杂糅代码,并不会对其产生什么影响
常见的考点是利用.htaccess进行操作,.htaccess文件对其文件内容的格式很敏感,如果有杂糅的字符,就会出现错误,导致我们无法进行操作,所以这里我们必须采用注释符将杂糅的代码进行注释,然后才可以正常访问
strip_tags绕过
1 | <?php exit; ?>实际上是一个XML标签,既然是XML标签,我们就可以利用strip_tags函数去除它,而php://filter刚好是支持这个方法的。 |
但是我们要写入的一句话木马也是XML标签,在用到strip_tags时也会被去除。
注意到在写入文件的时候,filter是支持多个过滤器的。可以先将webshell经过base64编码,strip_tags去除死亡exit之后,再通过base64-decode复原。
1 | php://filter/string.strip_tags|convert.base64-decode/resource=shell.php |
PHP漏洞函数
intval
intval函数可以获取变量的整数值
1 | int intval(var,base) |
如果 base 是 0,通过检测 var 的格式来决定使用的进制:
1 | 如果字符串包括了 "0x" (或 "0X") 的前缀,使用 16 进制 (hex);否则, |
当过滤某个数字时,我们可以利用它的进制转换来绕过
1 | <?php |
如果是一个弱比较a==b时
1 | 成功时返回 var 的 integer 值,失败时返回 0。空的 array 返回 0,非空的 array 返回 1。 |
当过滤某个数字的时候,可以通过输入小数来绕过
1 | echo intval(4.2); // 4 |
单引号传值时,只识别字母前面的一部分,而当进行get传参时,是默认加单引号的
1 | echo intval(1e10); // 10000000000 |
array_search()
array_search() 函数在数组中搜索某个键值,并返回对应的键名。
当未选择strict参数时(false),默认使用弱比较
== ===
1 | ==:先将字符串类型转化成相同,再比较 |
例如:0=='abc'为true
补充:**> <如何强比较**
1 | ($a > $b) && (gettype($b) == gettype($a)) |
‘’ “”
1、对变量的解析不同
PHP 会解析双引号中的变量,而不会解析单引号中的变量。
如果使用单引号定义的字符串中出现变量,在输出时变量会被原样输出,不会解析成变量的值。而如果使用双引号定义的字符串中存在变量,在输出时变量会被解析为具体的值
需要注意的是,虽然双引号定义的字符串能够解析变量,但是如果变量后边还有字符串的话,就需要将变量与后面的字符串使用空格分开,或者使用大括号{ }将变量包裹起来。如果不这么做的话,很可能会造成意想不到的结果
2、转义的字符不同
单引号和双引号中都可以使用转义字符\,但是,在单引号定义的字符串中只能转义单引号和转义符本身,而在双引号定义的字符串中,PHP 可以转义更多的特殊字符。
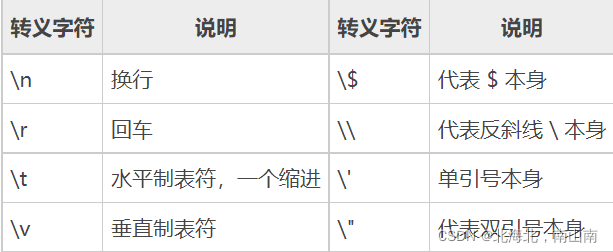
3、解析速度不同
因为单引号不需要考虑变量的解析,所以处理速度比双引号要快,我们在定义字符串时应该尽量遵循能用单引号尽量用单引号的原则。
assert
assert()函数其实是一个断言函数。
assert函数在php语言中是用来判断一个表达式是否成立。返回true or false;
1 | assert ( mixed $assertion [, string $description ] ) : bool |
preg_replace
preg_replace函数执行一个正则表达式的搜索和替换。
1 | mixed preg_replace ( mixed $pattern , mixed $replacement , mixed $subject [, int $limit = -1 [, int &$count ]] ) |
1 | $pattern: 要搜索的模式,可以是字符串或一个字符串数组。 |
如果 subject 是一个数组,
preg_replace()返回一个数组,其他情况下返回一个字符串。如果匹配被查找到,替换后的 subject 被返回,其他情况下 返回没有改变的 subject。如果发生错误,返回 NULL。
这个函数有个 /e 漏洞,/e 修正符使 preg_replace() 将 replacement 参数当作 PHP 代码进行执行。如果这么做要确保 replacement 构成一个合法的 PHP 代码字符串,否则 PHP 会在报告在包含 preg_replace() 的行中出现语法解析错误。
1 | /g 表示该表达式将用来在输入字符串中查找所有可能的匹配,返回的结果可以是多个。如果不加/g最多只会匹配一个 |
例如
1 | preg_replace("ab/e",system("ls"),"abc") |
服务器端模板注入(SSTI)
服务器端模板注入是指攻击者能够使用模板语法将恶意有效负载注入模板,然后在服务器端执行该模板。注入任意模板指令以操纵模板引擎,使他们能够完全控制服务器。
1 | 当用户输入连接到模板中而不是作为数据传递时,就会出现服务器端模板注入漏洞 |
1 | 传统静态模板:(不会产生此漏洞) |
常见的模板引擎
PHP
1 | 1.Smarty:Smarty算是一种很老的PHP模板引擎了,非常的经典,使用的比较广泛 |
Java
1 | 1.JSP |
Python
1 | 1.jinja2:flask jinja2一直是一起说的,使用非常的广泛 |
gopher
隐写
NTFS文件流隐写
特征:
注意:在CTF 题目中,给的ntfs隐写文件是在压缩包内的,需要用WinRAR进行提取,不然会造成数据流丢失
snow隐写
特征:文件有很多空格和tab
工具:snow隐写
MP3 private_bit隐写
特征:用010Editor打开可以看到struct MPEG_FRAME mf[0]//struct MPEG_HEADER mpeg_hdr下存在uint32 private_bit : 1,值为0/1
工具:010Editor+MP3扩展
1 | Linux:若010editor的试用期到了,删除 010 Editor.ini 文件 |
图片宽高修改
特征:
1.010Editor打开后参数与属性内参数不一致
2.010Editor打开后报Error:CRC Mismatch
Stegsolve
参数说明
1 | File Format:文件格式,这里你会看见图片的具体信息 |
关于Data Extract的参数
ZIP伪加密
1.压缩源文件数据区:
1 | 50 4B 03 04:这是头文件标记 (0x04034b50) |
2.压缩源文件目录区:
1 | 50 4B 01 02:目录中文件文件头标记 (0x02014b50) |
3.压缩源文件目录结束标志:
1 | 50 4B 05 06:目录结束标记 |
判断是否加密
全局方式位标记的四个数字中只有第二个数字对其有影响,其它的不管为何值,都不影响它的加密属性,即:
第二个数字为奇数时 –>加密
第二个数字为偶数时 –>未加密
无加密
压缩源文件数据区的全局方式位标记应当为00 00 (50 4B 03 04 14 00 后)
且压缩源文件目录区的全局方式位标记应当为00 00 (50 4B 01 02 14 00 后)
伪加密
压缩源文件数据区的全局方式位标记应当为 00 00 (50 4B 03 04 14 00 后)
且压缩源文件目录区的全局方式位标记应当为 09 00 (50 4B 01 02 14 00 后)
真加密
压缩源文件数据区的全局方式位标记应当为09 00 (50 4B 03 04 14 00 后)
且压缩源文件目录区的全局方式位标记应当为09 00 (50 4B 01 02 14 00 后)
不过也不一定对,可以用ZipCenOp.jar判断
1 | java -jar ZipCenOp.jar r 1.zip |
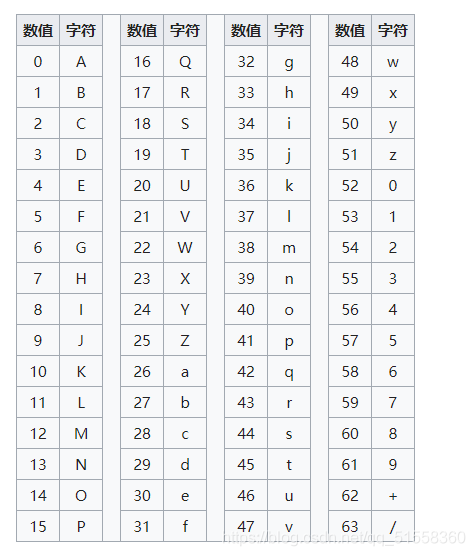
Base家族
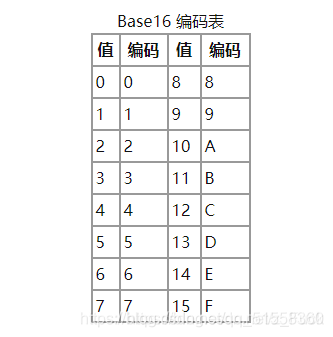
Base16
1.将数据(根据ASCII编码,UTF-8编码等)转成对应的二进制数,不足8比特位高位补0.然后将所有的二进制全部串起来,4个二进制位为一组,转化成对应十进制数.
2.根据十进制数值找到Base16编码表里面对应的字符.Base16是4个比特位表示一个字符,所以原始是1个字节(8个比特位)刚好可以分成两组,也就是说原先如果使用ASCII编码后的一个字符,现在转化成两个字符.数据量是原先的2倍.
1 | import base64 |
Base32
Base32编码使用32个ASCII字符(字母A-Z和数字2-7)对任何数据进行编码,Base32与Base64的实现原理类似,同样是将原数据二进制形式取指定位数转换为ASCII码。首先获取数据的二进制形式,将其串联起来,每5个比特为一组进行切分,每一组内的5个比特可转换到指定的32个ASCII字符中的一个,将转换后的ASCII字符连接起来,就是编码后的数据。
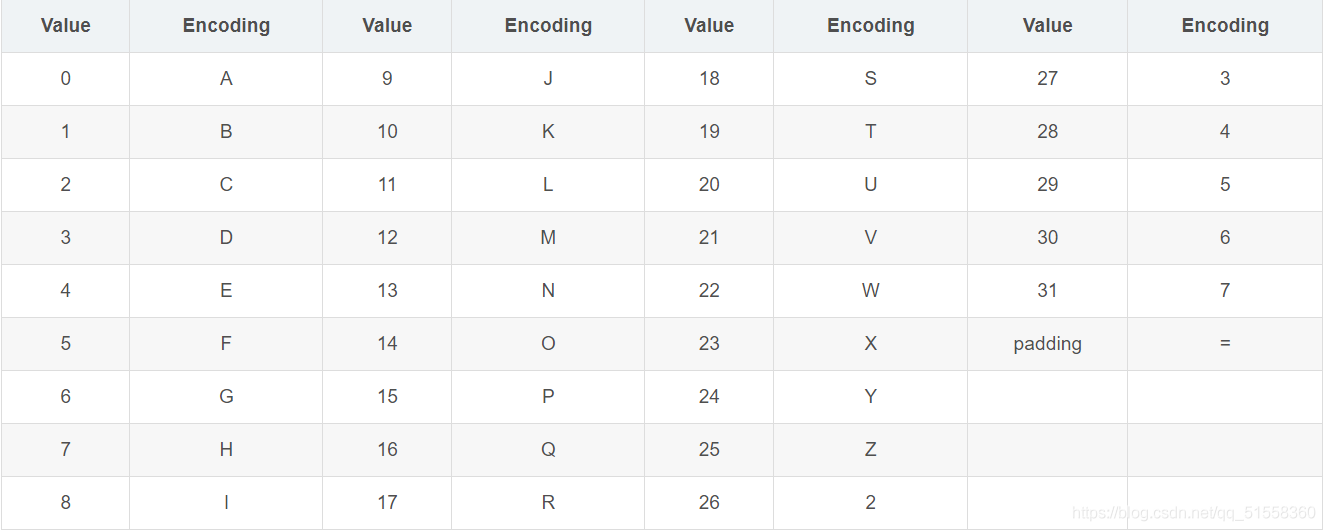
另外一种字典定义,即Base32十六进制字母表。Base32十六进制字母表是参照十六进制的计数规则定义:
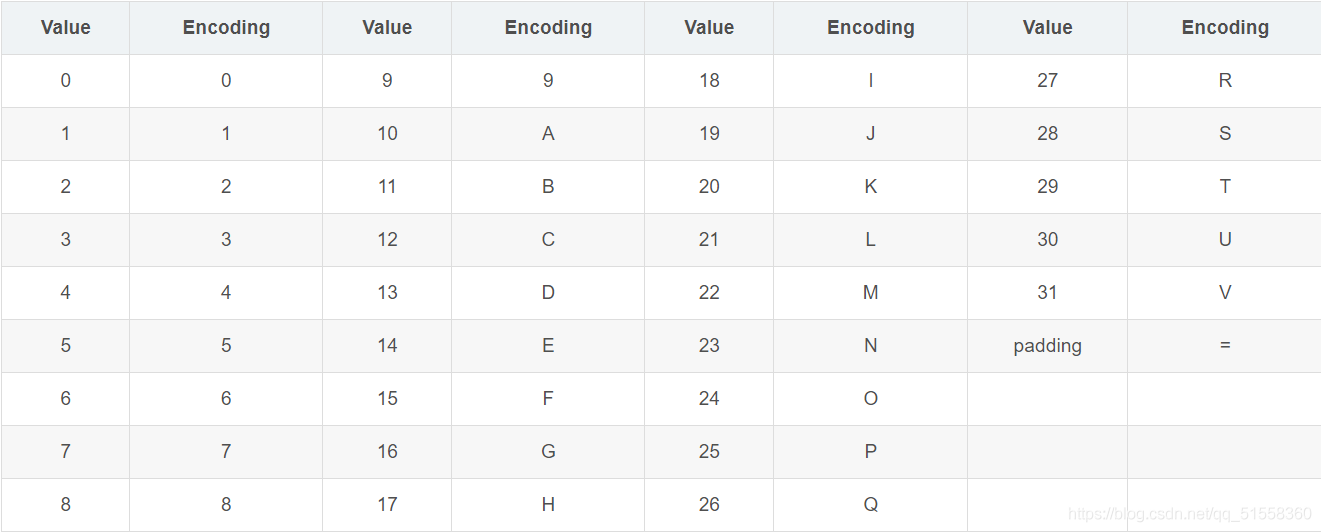
由于数据的二进制传输是按照8比特一组进行(即一个字节),因此Base32按5比特切分的二进制数据必须是40比特的倍数(5和8的最小公倍数)。例如输入单字节字符%,它对应的二进制值是100101,前面补两个0变成00100101(二进制值不足8比特的都要在高位加0直到8比特),从左侧开始按照5比特切分成两组:00100和101,后一组不足5比特,则在末尾填充0直到5比特,变成00100和10100,这两组二进制数分别转换成十进制数,通过上述表格即可找到其对应的可打印字符E和U,但是这里只用到两组共10比特,还差30比特达到40比特,按照5比特一组还需6组,则在末尾填充6个=。填充=符号的作用是方便一些程序的标准化运行,大多数情况下不添加也无关紧要,而且,在URL中使用时必须去掉=符号。
1 | import base64 |
Base36
Base36是一个二进制到文本编码表示方案的二进制数据以ASCII通过将其转化为一个字符串格式基数-36表示。选择36十分方便,因为可以使用阿拉伯数字 0–9和拉丁字母 A–Z [1](ISO基本拉丁字母)表示数字。
每个base36位需要少于6位的信息来表示。
Base58
Base58是用于Bitcoin中使用的一种独特的编码方式,主要用于产生Bitcoin的钱包地址。
相比Base64,Base58不使用数字”0”,字母大写”O”,字母大写”I”,和字母小写”l”,以及”+“和”/“符号。
Base62
Base62编码将数字转换为ASCII字符串(0-9,a-z和A-Z),反之亦然,这通常会导致字符串较短。
26个小写字母+26个大写字母+10个数字=62
Base64
Base64可以将ASCII字符串或者是二进制编码成只包含A-Z,a-z,0-9,+,/ 这64个字符
这64个字符用6个bit位就可以全部表示出来,一个字节有8个bit位,那么还剩下两个bit位,这两个bit位用0来补充
如果要编码的字节数不能被3整除,最后会多出1个或2个字节,那么可以使用下面的方法进行处理:
(1)先使用0字节值在末尾补足,使其能够被3整除,然后再进行Base64的编码
(2)在编码后的Base64文本后加上一个或两个=号,代表补足的字节数。
也就是说:
当最后剩余两个八位(待补足)字节(2个byte)时,最后一个6位的Base64字节块有四位是0值,最后附加上两个等号;
如果最后剩余一个八位(待补足)字节(1个byte)时,最后一个6位的base字节块有两位是0值,最后附加一个等号。

Base85
通过使用五个ASCII字符来表示四个字节的二进制数据(使编码量1 / 4比原来大,假设每ASCII字符8个比特),它比更有效UUENCODE或Base64的,它使用四个字符来表示三个字节的数据(1 / 3的增加,假设每ASCII字符8个比特)。
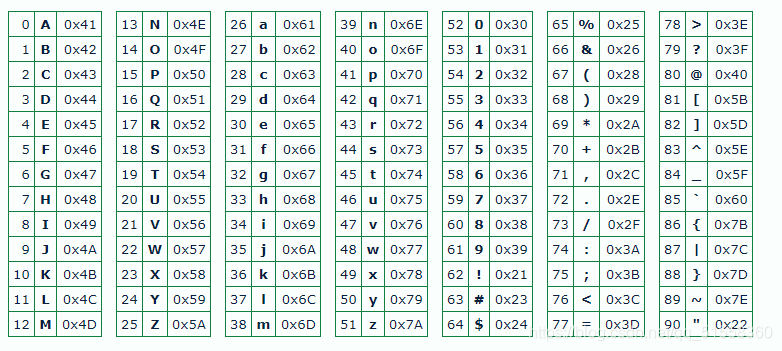
Base91
base91需要91个字符来表示ASCII编码的二进制数据。 从94个可打印ASCII字符(0x21-0x7E)中,以下三个字符被省略以构建base91字母:
1 | -(破折号,0x2D) |
加密
云影加密
特征:只有01248
原理:通过0分割,分割后每位数相加,按照1-26->A-Z的字典解密
举例:
1 | 884080810882108108821042084010421 |
rabbit加密
特征:rabbit加密后字符串开头为U2FsdGVkX1
BrainFuck
特征:由8种运算符组成
1 | > < + - . , [ ] |
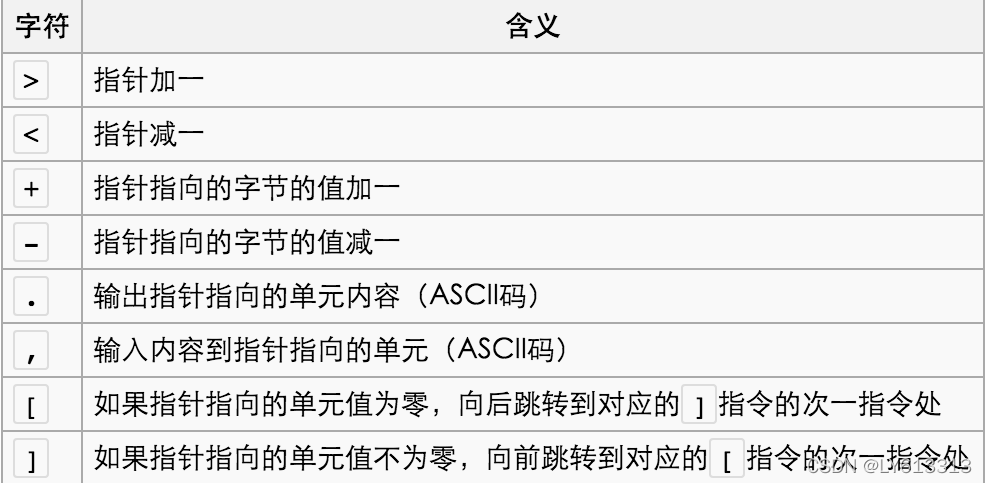
编解码:brainfuck